
Building a bytecode interpreter

A bytecode interpreter executes instructions in bytecode format. This contrasts our tree walker interpreter, which executes AST nodes. Bytecode is a low-level platform agnostic intermediate representation of our compiled program that executes on a bytecode virtual machine. A good analogy is that our virtual machine is the CPU while the bytecode is the machine code for the CPU. Python and Java are popular examples of languages that use bytecode interpreters. The Java Virtual Machine (JVM), the official name for the Java byte code interpreter, has been so successful that other languages such as Kotlin, Scala, Groovy, Closure and Jython (Python in Java) have been implemented to target it. So bytecode interpreters are a widely used technology.
Figure 1.0 below is a schematic for the Sox bytecode interpreter. The components within the dotted lines will be implemented in the next series of writeups. These include -
Bytecode instructions
A compiler
A virtual machine.
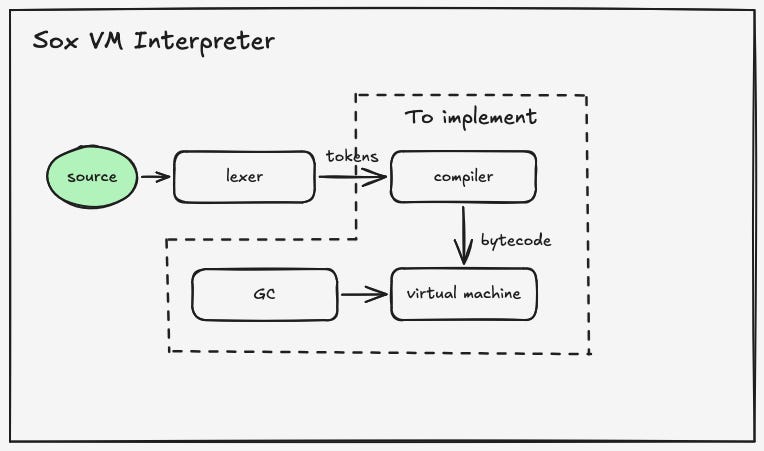
How it will all work.
Scanning - The lexer breaks our source code into tokens just as in the tree walker interpreter. We do not need to do anything new here.
Compilation - This replaces the parser component from the tree walker interpreter. This will be a two-step involving -
Parsing the source tokens, and
Emiting bytecode for parsed tokens.
Interpretation by the virtual machine - The virtual machine reads and executes the bytecode instructions one at a time. A virtual machine may translate bytecode into platform-specific machine code or directly execute operations represented by the bytecode instruction. In this case, the virtual machine directly executes operations represented by the byte code instruction.
Garbage collection - This will handle freeing of resources that are no longer used. The algorithm used here will be a very rudimentary mark-and-sweep garbage collection algorithm.
Benefits.
The primary benefit of the bytecode virtual machine that is worth mentioning is that it is more efficient than the tree-walker interpreter. The efficiency of our bytecode interpreter is somewhere between our tree walker interpreter interpreter and an implementation in native code. This performance boost is due to several reasons key among which is spatial locality of instructions. This means that because bytecode instructions unlike our AST are more compact (laid out very close to one another in memory), the CPU can load more instructions into memory at once leading to faster execution.
Next up we will look at how the foundations of the virtual machine which although it sounds complicated is remarkably simple to implement.